本文承自字符编码概论。我们已知在字符编码中有字符集与编码方式之分,那么在正则表达式中,如何处理两者的关系?换言之,由正则表达式编译而来的有限状态机,是匹配的我们直观看到的字符,还是(临时)存储在磁盘中的二进制流?
软件中的字符匹配
在Notepad++中,如果通过表面的字符搜索,那么匹配结果与字符编码无关;如果通过编码值进行搜索,则匹配结果与字符集有关。似乎只有在UTF-8的情况下才可以使用字符组。
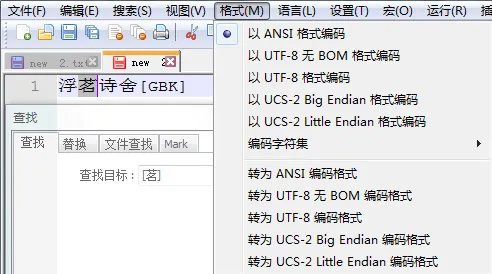 GBK编码文件字符查找 GBK编码文件字符查找 | 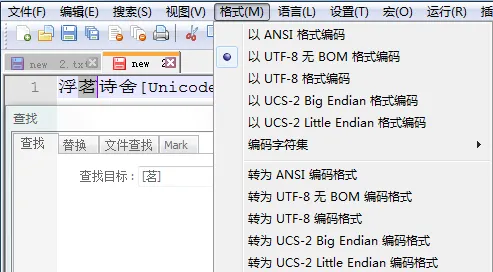 Unicode编码文件字符查找 Unicode编码文件字符查找 |
|---|
在GBK编码的文件下,如果使用字符组[茗-齿]匹配,将会提示正则表达式有误;而在UTF-8编码下使用字符组[茗-齿]匹配,则可以匹配得到“茗,诗”两字。UTF-8编码下,Notepad++中可以使用[\x{num}]查找字符,比如使用\x{8317}可匹配“茗”字;也可以使用字符组进行匹配;但是GBK编码下,则无法使用[\x{8317}]进行匹配,将提示“正则表达式错误”。
Unicode字符查询及输出
可在http://www.unicode.org/cgi-bin/GetUnihanData.pl页面查询中文字符值;word中提供了根据字符值输出字符的工具。插入=>符号=>其他符号:
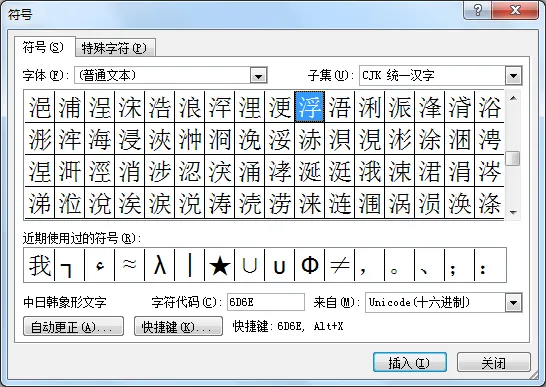 word插入“浮”字 word插入“浮”字 | 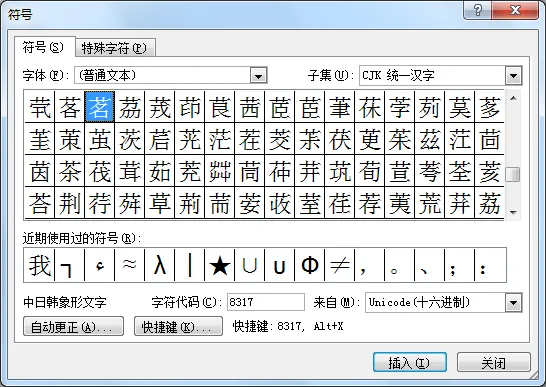 word插入“茗”字 word插入“茗”字 |
|---|
当然也可以根据Unicode字符值插入其他符号。不过word中收入的字符有限,后期扩充的Unicode字符,word不一定能够输出。通过Alt+小键盘数字也可以打出特殊字符,不过我试得不多。由于Unicode字符值是有序的,所以可以通过字符组匹配字符。比如在U+6D6E~U+8317之间,可以匹配“浮,茗,舍”。
正则表达式引擎与流派
正则表达式是一块相当复杂的技术地带,仅其历史估计就可以写上几十万字。漫长的历史造成了正则支脉繁多,不同工具中使用了正则也因此不同。简提其中的两个概念:引擎(engineer)与流派(falvor)。引擎主要指正则的实现方案,包括DFA,NFA,POSIX及他们的混合。流派指正则支持的不同的语法功能、支持元字符集的差异。故可知,当希望写出高效的正则表达式时,需要研究一下正则引擎;在平时使用时,需要研究一下当前工具使用的正则流派、支持的语法功能。不同的工具或编程语言可能支持不同的引擎或流派,《精通正则表达式》中给出了常见工具的正则表达式信息。在Notepad++中,使用[\x{num}]来匹配Unicode字符,在javascript中(在此站点测试),使用[\u_num_]匹配。
在看此方面的资料时,也愈发感到了Unicode的复杂。它可不只想把所字符囊括进来,还想尽可能的把字符之间的关系(a与A;Ï与I)也表达进来;还想保持与ASCII编码兼容,以至于同样外形的字符可能有不同的编码,如Ι(U+0399)和I(U+0049),在Notepad++中你用字符[I]是无法两个都匹配的;有时候,一个字符可能对应了两个代码点(code point),那你说点号(.)是匹配代码点还是匹配字符呢。总之Unicode给正则表达式的实现惹提供了相当大的挑战性,因为正则表达式希望实现在字符语义层次(比如用\w可以表示任何语言中的单词相关字符),而非字符编码层次。可以想见正则表达式实现内部对各种语言的处理得有多复杂。
本文小结
写得不够深入,定位不甚明确。以后在涉及不同语言时,再写语言中正则表达式与字符编码的关系。
参考资料
- 《精通正则表达式》,3ed。Jeffrey E.F. Friedl著,余晟译。电子工业出版社,2007年。
评论